Upload
01 PDFs, scans, spreadsheets, Office files, forms, cases, and batches.AI document processing
Documents into data.
State-of-the-art intelligent document processing.
Extract structured data from complex documents, prove every field, and ship the workflow into production systems.
State-of-the-art Intelligent document processing
Read
02 OCR reads tables, forms, handwriting, and long document layouts.Extract
03 Typed JSON with source locations, lookup files, knowledge-base search, and formulas.Automate
04 SDKs, visual flows, edge runtimes, webhooks, CSV, and Excel exports.Quality signal
Highest-quality intelligent document processing for production workflows.
Source evidence
Every extracted field can be tied back to page images, boxes, traces, and job artifacts.
Long document depth
OCR, markdown splitting, map-reduce, and document outlines keep complex packets readable.
Lookup and evaluation
Ground extraction with lookup files, search knowledge bases, and evaluate documents against evidence.
Control plane
One platform from first extraction to live workflow.
DocuDevs combines a developer API with an operations UI, so teams can prototype, inspect, automate, and govern document processing without rebuilding the same plumbing.
Document Workbench
Prototype prompts, schemas, OCR settings, source locations, lookup files, knowledge bases, tracing, and map-reduce in one workspace.
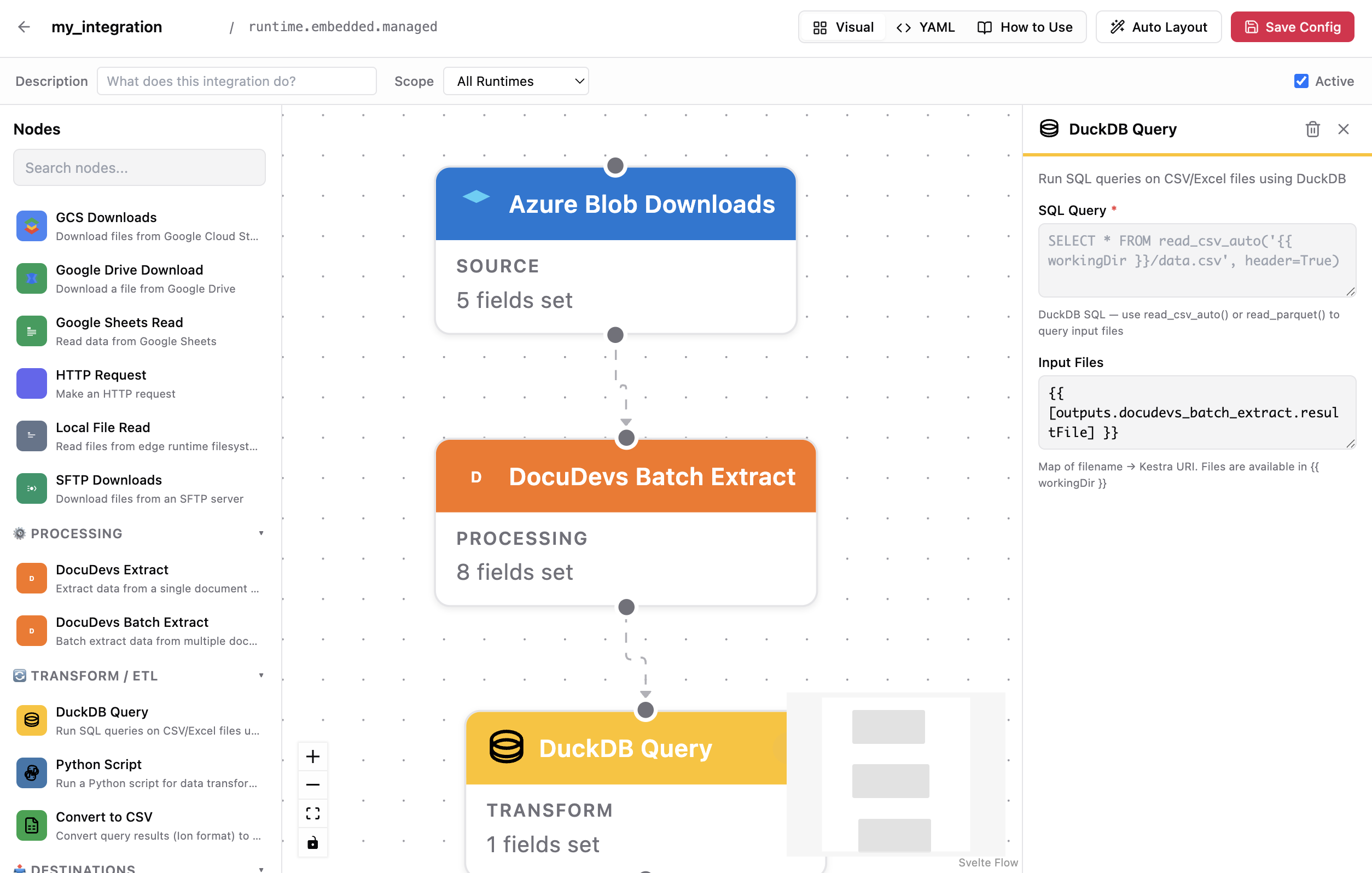
Integration Builder
Build document workflows in a fully integrated DocuDevs canvas. Scheduling, runtime handoff, YAML, and connector plumbing are handled for you.
Edge runtimes
Run embedded integrations near private files while the cloud control plane manages configs, status, and orchestration.
Batch operations
Process folders of documents, track progress, and download normalized JSON, CSV, or Excel outputs.
Agent assisted setup
Describe the outcome you need and let the agent draft extraction instructions, schema fields, lookup plans, and processing plans.
Provider control
Use DocuDevs managed OCR and LLMs, or connect your own Azure Document Intelligence, OpenAI, and Azure OpenAI providers.
Integration builder
Build document workflows in an integrated canvas.
DocuDevs gives teams a visual builder for intake, extraction, transforms, destinations, and runtime scope. It benefits from the Kestra ecosystem underneath, but users stay in DocuDevs: no separate workflow platform to learn, deploy, or operate.
- Fully integrated visual canvas, YAML generated only when needed
- Connector reach from the Kestra ecosystem without separate orchestration ops
- Cloud or edge runtime execution handled inside DocuDevs
Builder integrated
Connectors Kestra-backed
Ops managed
Visual mode, YAML, run instructions, scopes, and save config live in one builder.
Developer tools
Use the SDK when code is right. Use the builder when workflow is right.
The same extraction engine powers API requests, UI jobs, saved configurations, batch runs, and edge flows.
Typed extraction
from docudevs import DocuDevsClient
from pydantic import BaseModel
client = DocuDevsClient(token="your-api-key")
class Shipment(BaseModel):
container_id: str
port_of_loading: str
gross_weight_kg: float
result = client.extract(
"bill-of-lading.pdf",
schema=Shipment,
source_locations=True
)Validated object
Shipment( container_id="MSCU4829910", port_of_loading="Helsinki", gross_weight_kg=21740.0 )
Document pipeline
A clean path through messy inputs.
Every document run is observable: queued, processed, traced, stored, and ready for the next system, including lookup and knowledge-base evidence.
Describe the data
Start from a prompt, JSON schema, saved configuration, lookup file, knowledge base, template, or agent drafted plan.
Read the document
OCR converts layout, tables, figures, spreadsheets, and long reports into model-ready context.
Extract and verify
Structured output is validated, enriched with source evidence, grounded by lookup and knowledge-base results, and tracked as an async job.
Ship the result
Return JSON to your API, export CSV or Excel, fill templates, or push through an integration flow.
Use cases
Built for the documents that slow teams down.
Start with a single extraction and grow into cases, templates, quality checks, batch exports, lookup files, knowledge-base evaluation, and integration flows.
Purchase orders and invoices
Contracts and legal reviews
Claims and case files
Shipping and customs documents
Financial reports and tables
Compliance packets and audit evidence
Start fast
Pick the entry point that matches your team.
Ready
Turn the next document workflow into a production system.
Start with the full platform, a token pack, and the same API capabilities you can keep in production.